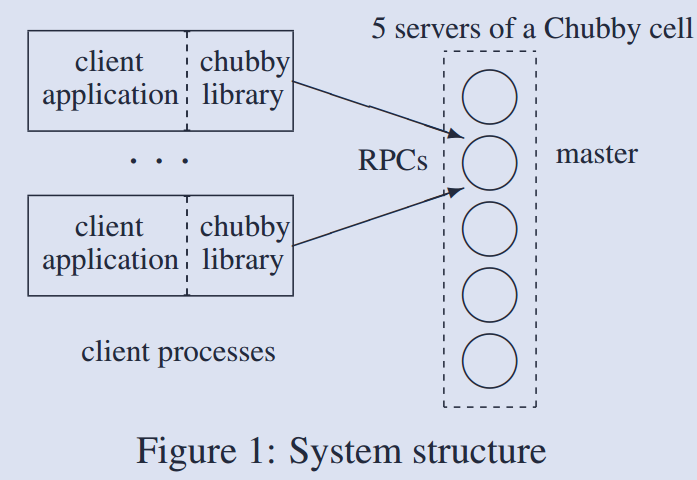
Raft 协议是一个分布式共识(consensus)算法, 可以参考 ATC-Raft 和 Thesis-Raft 这两篇文章. 两篇文章是同一个作者, 第一篇是小论文, 第二篇是大论文, 阐释地更加全面、详细.
Raft 协议将 consensus problem 划分为下面的几个子问题, 分别提出对应的解决方案:
- Leader Election
- Log Eeplication
- Safety
上面讨论的是集群配置不变(即节点数量、地址等不变)的情况, 而实际中经常需要增减节点、修改地址. 为此, Raft 算法中还包含了两种 Membership Change 方法. 前者一次只增减一台节点, 清晰易懂. 后者允许增减任意数量的节点, 但是更加复杂.
- Single-Server Approach
- Arbitary Configuration Change
另外, 当日志逐渐增长, 会占用大量的磁盘空间, 并且重启时恢复到最新状态的速度会大幅降低. 为此, Raft 算法中包含了 Log Compaction 机制. 大论文中提到了四种, 对第一种做了详细的介绍. 小论文中只介绍了第一种.
- Memory-Based Snapshots
- Disj-0Based Snapshots
- Log CLeaning
- Log-Structured Merge Trees
另外, 这里还对客户端与 Raft 模块间的交互进行说明, 包括:
- How clients find the cluster
- How clients find the leader
- How Raft provides linearizable consistency
- How Raft can process read-only querirs more efficiently
下面对各个部分进行详细说明. 实际上有的部分没写 :)
Background
为了在分布式系统中实现容错, 一个常用的办法是采用复制状态机(replicated state machine). 首先, 给定多个初始状态相同的节点, 在后续的操作中, 将每个操作以相同顺序应用到每一台节点上. 那么, 在操作正常执行的情况下, 每台节点在任何时刻就具有相同的状态. 这样, 我们就能保证即使有部分节点出现故障, 只要有节点存活, 整个系统就能满足可用性.
这是理想情况的结果, 实际中要满足可用性还存在许多问题. 例如:
- 如何确定操作正常执行, 当执行结果不同时如何处理?
- 如何保证系统的可扩展性?
为了解决这些问题, 首先需要对节点的错误类型做出限定, 这里假定所有的节点都是 fail by stopping的, 也就是说发生错误后可以重启, 通过读取已经持久化的状态信息来恢复到某个正确的状态, 并重新加入集群.
当不同节点的状态不一致时, 如何确定正确状态? Paxos 提出: 少数服从多数(quorum). 即根据大多数节点的状态确定整体的状态, 例如在一个有5个节点的集群中, 用户请求变量 x 的值, 在至少3个节点中 x 的值为1111, 那么我们就认为 x 的值是1111. 在这样的系统中, 只要有大多数节点是可用的, 就能保证可用性. 那么, 要保证系统能容忍 n 个节点的错误, 就需要至少 2n+1 个节点.
一个操作抽象为一个 log entry. 初始时, 节点日志(log)为空, 当接收到操作命令时, 将其转化为一条日志(log entry), 附加到(append)每个节点的日志的末尾, 并将日志持久化, 再执行(apply)该操作. 这样, 节点重启时就可以通过再次执行(重放, replay)此日志, 来达到一个正确的状态. 但是, 此状态很可能是过时的(tale), 我们需要其他机制来使重启的节点更新到最新状态, 例如其他的具有最新的日志的节点向其发送缺少的日志.
从上面的分析可以看出, 问题的核心在于 日志的管理, 即保证大多数节点日志的状态一致. 那么如何确定哪些节点具有最新的日志, 如何决定由谁来更新新加入节点的日志...? Raft 算法就是为了解决这些问题, 最终实现 sonsensus.
Overview
Raft 算法首先从集群所有节点中选举出一个 Leader, 其余节点称为 Follower, 由 Leader 来负责管理日志. Leader 负责处理用户的请求, 并将之转化为日志, 并复制到其他的节点上. 当 Leader 将日志复制到大多数节点时, 就能将之应用(apply)到状态机, 并将之 commit, 最后将结果返回给用户.
为了保证日志条目(log entry)的有序性, 算法将时间划分为不同的 term, term 是一个连续的单调递增的整数. 当节点中发生 Leader 选举时, term 加一, 当节点观察到比自身更大的 term 时, 切换到该 term. 同时, 每条日志具有一个 index 来唯一标记, index 同样单调递增, 新的日志的 index 大于旧的日志的 index. 算法中用 term 和 index 来标记日志.
这里有点不太理解: 看论文中 index 是唯一的, 但是这里只保证在每个 term 中 index 唯一应该也没有问题.
为了严格证明算法的正确性, Raft 保证下面几条性质:
Election Safety:
最多只有一个节点成为 Leader.
Leader Append-Only:
Leader 不会删除或覆盖自身的日志, 只会不断将新的日志附加到日志末尾.
Log Matching:
如果两条日志(log entry)的term和index相同, 那么从这两条日志开始, 她们和她们前面的所有日志都对应相同.
Leader Completeness:
如果一条日志在一个 term 中被 commit 了, 那么在该 term 之后的所有 term 中, 这些 term 的 Leader 的日志中都包含这条日志.
State Machine Safety:
如果一个节点应用了一条日志到状态机, 那么其他机器不会应用一个 index 与此日志相同, 内容却不同的日志到状态机. 也就是说, 对于不同节点应用到状态机的日志, 只要 index 相同, 日志就是相同的.
Raft 通过远程过程调用(RPC)来实现节点间的通信, 定义了下面几种 RPC:
- RequestVote RPC: 由 candidate 调用, 用于进行 leader 选举.
- AppendEntries RPC: 由 leader 调用, 用于复制日志或作为心跳信息(维持leader).
Leader Election
节点有三种状态: follower, candidate, leader. 节点通过下面的变量来维护其状态:
- 需要持久化的
- currentTerm: 节点见到的最新的 term(初始为0, 单调递增)
- votedFor: 为某个节点的id, 表示节点在当前同意该节点成为 leader. 可以为null.
- log[]: 日志. 每条日志包含对应的命令.
- 不需要持久化, 在内存维护的
- commitIndex
- lastApplied
- leader 专有的(不需要持久化, 在内存维护)
- nextIndex[]
- matchIndex[]
初始时节点都是 follower, 此时节点并不知道集群中是否存在 leader, 因此会等待一段时间, 这段时间称为 election timeout. 如果这段时间内节点收到 leader 的消息, 并且 leader 的 term 大于等于自身的 term, 就设置 voteFor 为 leader id, 继续保持 follower 状态. 当这段时间过后, follower 没有收到来自 leader 的消息时, 就可以认为集群中没有 leader, 并转移到 candidate 状态, 进行 leader 选举. 下面介绍选举过程.
节点首先增加其 term, 并转移到 candidate 状态, 重新设置 election timeout. 然后将 voteFor 设置为自己的id(我选我 O(∩_∩)O), 并并发地对集群中的其他节点调用 RequestVote RPC. 节点等待 RPC 的返回结果, 直到出现下面的事件:
- 赢得选举
- 其他节点成为 leader
- election timeout 超时
第一个事件很容易理解, 当大多数 RPC 调用成功返回时, 表明大多数节点同意该节点成为 leader, 选举成功. 此时, 节点转移到 leader状态, 并立即并发地向其他节点发送心跳通知自己成为 leader, 防止其他节点开始新的选举. 这里有几个问题需要解释一下:
- 节点的投票机制: 采取先到先得的机制, 对于 term 相同的 RequestVote RPC, 节点将会投给第一个到的调用者. (term 不同时在Safety部分说明)
- "大多数节点同意"的限制保证了一个 term 只会存在至多一个 leader, 也就保证了 Election Safety.
第二个事件: 当节点收到某个节点的心跳信息(表明该节点成为 leader)时, 并且该信息表明此节点的 term 大于等于自身的 term 时, 节点转移到 follower, 承认该节点是 leader(设置 voteFor 为该节点的id). 当节点自身 term 较大时, 拒绝承认该节点为 leader, 并返回自己的 term, candidate 状态不变.
第三个事件: 当上述两个事件在一段时间内都没有发生时, 就发生此事件. 其原因可能是由于多个节点同时开始选举, 因而都不能满足"大多数节点同意"的限制. 这个情况会带来一个问题:
- 这时如果不加处理, 这些节点会同时发生 election timeout 超时, 同时开始新一轮选举, 再次超时... 如此循环下去, 导致系统无法选举出 leader, 因而不可用.
为了避免这个问题, Raft 每次设置 election timeout 时, 不是设为固定值, 而是设为一个区间内的随机值. 这样就能降低节点同时发起选举的概率, 如果同时发起选举后, 同时超时的概率同样会被降低.
下面再说明节点接收到 RequestVote RPC 时的处理过程.
1 | // Argument: term, candidateId, lastLogIndex, lastLogTerm |
candidate 需要将自身当前的最后一条日志的 index 和 term 作为参数发送给其他节点, 即上面的 lastLogIndex 和 lastLogTerm 参数.
值得注意的地方是节点判断是否同意 candidate 为 leader 时, 需要检查 candidate 的日志是否不落后于自身的日志. 此限制保证了前面的 Leader Completeness 性质. 我们在 Safety 部分做更详细的说明.
Log Replication
节点成为 leader 后, 就可以响应用户的请求, 并将日志复制到其他节点. leader 将用户的请求转化为一条日志, 首先append到自身的日志记录, 然后调用 AppendEntries RPC, 并行地向其他节点发送此日志, 当大多数节点的 RPC 成功返回时, 表明日志已经成功复制到大多数节点上. 此时节点可以将此日志应用到状态机, 并返回执行结果给用户(称日志 committed). 期间如果 RPC 失败或是没有相应, leader 会不断重复地对这些节点调用该 RPC, 直至成功. 当节点 commit 一条日志后, 就修改自身的 commitIndex 到对应值. 在 AppendEntries RPC 中, leader 会将其 commitIndex 作为参数发送给 follower, follower就可以据此来判断应该 commit 自身的哪些日志, 从而更新其状态机.
committed 是一种状态, 表明日志可以被应用(apply)到了状态机, 或者说已经复制到了大多数节点. 考虑到用户请求应该被顺序执行, 一条日志被 commit 就导致其前面的所有日志被 commit. 即将一条日志应用到状态机时会先将前面的没有 commit 的日志先应用到状态机. 在Safety部分还会说明, Raft 能保证一旦一条日志被 commit, 其后所有的 term 的 leader 中都会有这一条日志.
当一个节点收到 AppendEntries RPC 调用后, 其处理过程为:
1 | // Argument: term, leaderId, prevLogIndex, prevLogTerm, entries[], leaderCommit |
上面有几点需要注意:
节点接收到 AppendEntries RPC 后, 会检查本地是否有与 prevLogIndex 和 prevLogTerm 匹配的日志. 这里有两种情况. 一种是节点日志落后太多, 没有 index 为 prevLogIndex 的日志. 此时节点返回错误, 通知 leader 此消息. 另一种是存在 index 等于 prevLogIndex 的日志, 但是这条日志的 term 不等于 prevLogTerm. 这是怎么导致的? 是 leader 还是当前节点错误? 后文再做详细讨论. 这里只说明此时节点同样返回错误, 由 leader 进行处理. 另外强调一点, leader 是集群的管理者, 是不会错的, 如果发生错误, 说明那是个假 leader. :)
如果本地有与 prevLogIndex 和 prevLogTerm 匹配的日志, 就可以将 leader 传来的日志复制到本地. 这时是有可能出现这样的情况: 节点已经存在 entries 中的部分/全部日志. 例如, RPC 调用执行成功, 但是返回时出现错误, leader 重新调用, 这时传来的日志在本地已经存在. 节点检查本地的日志是否与 leader 传来的日志冲突(按对应顺序检查 index 和 term 是够相等), 如果发生重复, 将该条日志及其后面的所有日志全部删除, 再将 leader 传来的日志 append 到本地日志. 如此, 就完成了日志复制, 最后向 leader 返回相应信息即可.
上面提到的第一个限制保证了日志的一致性. 初始时日志显然是一致的. 添加日志时, 检查各个节点要添加的日志的前面一条日志是否相同, 相同才会添加. 这样就保证了各个节点日志的一致性. 当然, 这里会存在落后节点, 但是其状态是有效的, 并且 Leader 不断对其调用 AppendEntries RPC 可以使其日志逐渐同步到最新状态.
Safety
本部分着重于对算法正确性的说明, 对前面的 Leader Election 和 Log Replication 增加一些限制, 以保证算法正确性.
首先是对 Leader Election 的限制. 只有当 candidate 的日志是否不落后于自身的日志时, 节点才会同意 candidate 成为 leader. 这保证了 Leader Completeness 性质, 下面做详细阐述. 在某个 term 中, 当一条日志被 commit, 就说明该日志被复制到了大多数节点. 在其后的 term 中, candidate 要想成为 leader, 必须先获得大多数节点的同意. 也就要求 candidate 的日志不能落后于大多数节点, 即必须拥有大多数节点都有的日志. 而在前面的 term 中被 commit 的日志显然存在于大多数节点. 反之, 如果 candidate 不含前面的 term 中被 commit 的日志, 就不能得到大多数节点的同意, 也就不能成为 leader.
其次是对 commit log 的限制. 首先考虑论文中提到的一种情况, 如 Figure 1 所示(来源于大论文 Figure 7.3, 详细介绍参考论文中的说明). 这个例子的目的是为了说明对于旧的 term 中的日志, leader 不能根据日志是否已经复制到大多数节点来判断是否可以将此日志 commit. leader 只能按照前面所说的机制, 直接 commit 当前 term 的日志, 在 commit 当前 term 的日志时, 会先 commit 此日志前的未 commit 的日志. 这样就可以保证在之前的 term 中的日志得以被 commit. 图中最重要的部分在于说明了某个 term 中的一条日志可以先在一个 term 中被复制到小部分节点, 在后面的 term 继续复制到其他节点. 这是问题的核心原因.
 Figure 1: old term log commit
Figure 1: old term log commit
文章中还对 Leader Completeness 性质做了严格的证明. 这里不做赘述.
Cluster Membership Change
前面提到的机制都是针对集群中节点数量不变的情况, 实际中我们会需要在集群中增加或删除节点. 如果手动操作, 容易带来错误, 因此 Raft 提供了动态增删节点的机制.
我们称集群中的节点数量, 各个节点的地址为集群的配置. 每个节点都将集群的配置存储在文件中, 因此在集群中增删节点实际上就是对集群所有机器文件的修改. 这里的难点在于不能保证同时修改所有节点的配置, 这就可能会导致脑裂. 比如在一个有 3 个节点(s1, s2, s3)的集群中增加 2 个节点(s4, s5), 由于网络原因, s1, s2 节点仍然是旧的配置, s3, s4, s5 则是新的配置. 那么 s1, s2 就可以选举出一个 leader, s3, s4, s5 同样可以选举出一个 leader. 这就导致了错误. 因此, 需要更多的限制来保证安全性.
大论中提到了两种机制. 第一种一次只能增删一个节点, 方法简单, 容易理解. 第二种允许一次增删多个节点, 但是较为复杂.
第一种方法的核心在于: 一次只增删一个节点时, 旧的配置的和新的配置的节点不可能同时满足 quorum. 下面的 Figure 2 生动形象地说明了这一点(来源于大论文 Figure 4.3).
 Figure 2: The addition and removal of a single server from an even- and an odd-sized cluster
Figure 2: The addition and removal of a single server from an even- and an odd-sized cluster
增删节点的请求同样由 leader 负责, 这样的请求同样被作为日志, 并通过 leader 复制到其他节点. Raft 定义了 AddServer RPC 和 RemoveServer RPC 来处理这两种请求, 集群管理员可用通过对 leader 调用这两个 RPC 来增删节点. 下面介绍一下 leader 如何处理这两种 RPC 调用.
1 | // Argument: newServer |
值得一提的是, 修改配置不会使得集群停止相应用户的的其他请求. 当 leader 成功地将新的配置对应的日志复制到(新配置下的)大多数节点时, 就表明集群的配置已经修改, 就可以开始处理下一个集群配置修改请求. 如果删除节点的请求 commit, 就可以将该节点关闭.
这里还需要考虑前面的 Leader Election 和 Log Replication, 总的来说就是节点收到 RequestVote RPC 和 AppendEntries RPC 调用时, 即使调用者不再本地配置的节点中, 也会处理这些 RPC 调用.
当一个节点收到来自 leader A 的 AppendEntries RPC 时, 可能发现 A 并不在自己的配置节点中. 这时节点同样会处理该 RPC, 否则节点可能永远无法更新到最新配置. 例如, 集群新增一个节点后, 存在小部分节点没有更新到最新配置. 这时新加入的节点成为 leader, 将会继续将新的配置的日志复制到那些小部分节点, 而此时 leader 并不在这些节点的配置节点中.
当一个节点收到来自节点 A 的 RequestVote RPC 时, 可能发现 A 并不在自己的配置节点中. 此时节点同样会处理该 RPC.
第二种增删节点的方法则较为复杂, 但是能同时处理任意数量的节点增删. 下面对其过程做一个描述. 当 leader 收到管理员的改变配置的请求时, 会生成日志将新旧配置都记录下来, 然后将这条日志 append 到本地日志, 并将其复制到(新旧配置下的)其他节点. 任一节点收到该配置日志后, 都会立即切换到对应状态, 称为 \(C_{old,new}\).
此时集群中同时存在不同配置的节点, Raft 引入 joint consensus 来描述这种状态, 并规定:
- 日志将会被复制到新旧配置中的所有节点.
- 新旧配置中的节点都可以成为 leader.
- 对于处于 \(C_{old,new}\) 状态的节点, RequestVote RPC 和 AppendEntries RPC 调用要成功, 必须要分别得到新的配置和旧的配置中的大多数节点的同意.
一旦 leader 能 commit 此日志, 即新配置下的大多数节点均复制了此日志, leader 就会再将新的配置对应的日志复制到(新配置下的)其他节点, 复制成功的节点就会转移到 \(C_{new}\) 状态. 当此日志成功 commit 时, 集群配置就修改成功了. 集群状态变化如 Figure 3 所示(大论文Figure 4.8).
第三条限制就避免了集群中同时出现两个节点的错误, 但是却不能避免处于旧的配置的节点选举出 leader, 此时管理员可以再次发起请求.
 Figure 3: Timeline for a configuration change using joint consensus
Figure 3: Timeline for a configuration change using joint consensus
Log Compaction
显然, 按照上面的机制, 节点的日志会不断增长. 这会导致几个问题:
- 日志过长, 占用大量存储空间.
- 机器重启时需要重放日志, 重启花费的时间过长.
- 新增节点时, 需要复制大量的日志, 占用带宽过多, 花费时间过长.
因此, Raft 提出了 Log Compaction 机制来压缩日志长度, Raft 采用的方法是快照(Snapshotting). 大论文中提到了多种不同的快照方案, 这里只对基于内存的进行总结, 这也是小论文中采用的.
基本思想是每个节点独立的判断是否需要进行日志压缩, 节点可以根据日志长度或剩余空间等来进行判断. Snapshot 完成后, 就可以将 Snapshot 的最后一条日志及其前面的所有日志删除, 之前的快照也可以删除. Snapshot 需要记录下面的信息:
- 状态机状态
- 最后一条日志的 index, term(last included index/term)
- 节点最新的配置
虽然各个节点的 Snapshot 操作是独立进行的, 但是设想这样的情况, leader 进行一次 Snapshot 后, 发现某个节点的日志落后太多, 需要传送那些已经删除的日志给该节点. 这时候由于日志已经删除, 就需要将节点的 Snapshot 发送给该节点. 为此, Raft 定义了 InstallSnapshot RPC, leader 可以通过调用此 RPC 来将自身的 Snapshot 发送给其他节点. 节点对 InstallSnapshot RPC 的处理比较简单, 最重要的一点是有可能 Snapshot 对应的最后一条日志节点中也有. 这可能是由于延迟导致的, 这时节点不对本地日志做处理.
Conclusion
至此, Raft 就算基本介绍完了, 中间可能还有疏漏的信息, 就留在以后补了. 虽然 Raft 以简单作为她的一个优点, 但是还是有点复杂, 细节很多.