Chubby是谷歌提出的在分布式环境下方便节点间的协调的服务. 论文为: The Chubby lock service for loosely-coupled distributed systems
- Motivation
- Design
- Architecture
- Files, directories, and handles
- Locks and sequencers
- Events
- Caching
- Sessions and KeepAlives
- Fail-overs
Motivation
- 为primary election问题提供通用的解决方案, 不需要特别实现和人工干预.
- 为客户端提供 粗粒度 的同步, 协调服务, 解决客户端的共识问题.
- 可靠性和可用性, 支持大量客户端.
- 语义简单, 易于使用.
- 不要求提供高吞吐率.
Design
- 对外提供锁服务来说实现客户端间的协调, 比如客户端leader选举问题, 客户端向chubby申请获取锁, 获得锁的客户端即为leader. 这样可以保证即使只有一个客户端可用时, 客户端系统仍然可用. 这就相 当于将部分保证一致性的任务转移到了chubby.
- leader通过将信息写到小文件中来向其他节点广播消息.
- 客户端数量可能非常多, 因此需要允许大量客户端observe(观察?)上面提到的小文件, 并且不需要在 chubby端部署很多服务器.
- 客户端可能希望当观察的文件发生变化时得到通知, 因此可以使用事件通知机制, 在客户端订阅的事件发 生时向其发送通知, 减少客户端的polling.
- 需要支持 consistent caching 和访问控制.
- 使用粗粒度的锁(coarse-grained lock), 因为实际中客户端持有锁的时间可能达到几小时甚至几天, 并且锁请求的数量与事务的数量是弱相关的. 并且, 锁从一个客户端转移到另一个客户端的代价很大, 所 以不希望chubby服务的崩溃-恢复丢失对原来锁的记录, 导致客户端服务器重新获取锁.
Architecture
- chubby包含两部分: 服务器集群和库, 二者通过RPC通讯. 库可以与客户端应用链接, 为客户端提供接 口.
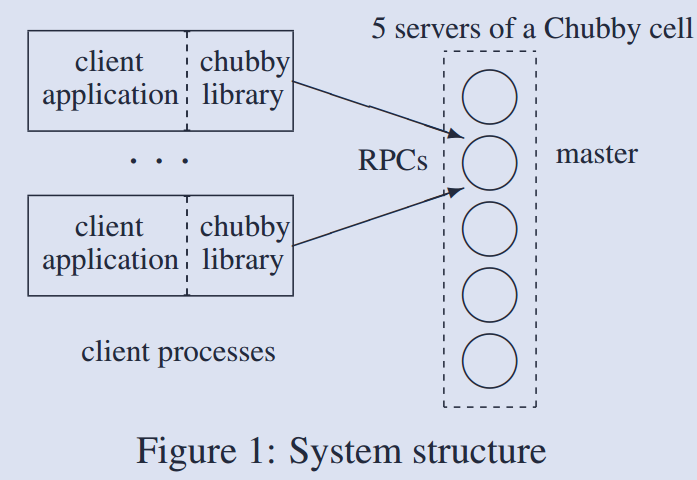
服务器集群通过一致性算法选举出leader, 并获得一个leader lease, 副本服务器在lease内不会选 举新的leader, lease可以由副本服务器定时更新(怎么实现的?怎么进行协商?), 以延长此lease. 副本服务器维护数据库的副本, 由master控制对数据库的读写, 副本服务器仅仅是按照master的要求更 新数据库?(什么意思? 只由master负责响应客户端的对请求吗?)
DNS保存了chubby服务器集群的地址列表, 客户端通过向表中的机器发送 master location request 来获得master的地址, 副本服务器将会返回master的位置(地址?). 客户端获得master的位置后, 将所有请求发送到master, 直到master停止回复(cease to respond, 什么意思?)或声明不再是master. 对于写请求, master将其通过一致性协议发送到所有副本服务器, 当大多数副本ack后, master即可向 客户端发送ack. (如果在这个阶段master lease到期, 怎么处理?) 对于读请求, 由master直接回复.
如果一个副本服务器崩溃, 并且数个小时没有恢复, replacement system 就会在从空闲机器池中 选择一个新的机器来代替它, 并更新DNS. master周期性地检查DNS, 发现这个更改后, 将此更新更新到 集群所有服务器的数据库中. 同时, 新的副本服务器通保存在文件服务器的备份和其他活动副本服务器(active replicate)的更新来 获得最近的数据库副本. 一旦这个新的副本服务器处理了一个当前master等待commit的请求, 即可参与 到将来的master选举, 在此之前不允许其参与.
Files, directories, and handles
chubby向客户端提供了一个类似Unix文件系统接口的接口, 逻辑上对外的数据结构是一个树状的文件 系统. 文件系统由文件和目录组成, 一个目录可以称为一个chubby cell, 作为一个独立的单位, 在cell 下可以进行如文件删除创建等操作.
文件和目录统称为node. 每个node都有很多元数据(meta-data).
- 3个ACL(access control list)名字, 分别用来控制对node的读, 写权限和修改ACL名字权限, 这 些名字分别对应了此cell中权限控制目录下的一个目录, 比如node abc写权限的名字为abc_wr, 那 么abc所在cell的权限控制目录下有一个目录abc_wr, abc_wr下的文件的名字就对应着一个对abc有 写权限的用户名. node可以是永久(permant)的或临时(ephemeral)的, 每个node可以被显式地删 除, 对于临时节点, 满足某些条件时会被自动删除. 比如没有客户端保持对临时节点的打开, 临时目录 下为空(目录下没有node). 经常用一个临时文件表示客户端是否存活.
- an instance number
- a content generation number(files only)
- a lock generation number
- an ACL generation number
成功打开一个node后可以获得一个handle, 以后可以用这个handle来对文件进行各种操作, 类似Unix 中的文件描述符. Unix中, 只有打开文件描述符时才会进行权限检查, 以后对fd调用操作函数时不会检查 权限, 但在chubby中, 会对每个操作进行权限检查. chubby周期性地检查打开文件/持有锁的客户端是否alive, 当发现客户端已经fail时, 会自动进行相应 处理. handle同样包含元数据:
- check digits: 防止恶意客户端猜测, 非法创建handle.
- a sequence number: master可以通过这个判断此handle是由自己生成还是之前的master生成的.
- mode information: provided at open time to allow the master to recreate its state if an old handle is presented to a newly restarted master. (当一个master fail-over之后, 收到一个fail-over前创建的handle, 可以用此handle的 mode information重建自己的状态?)
Locks and sequencers
- 每个node都可以作为一个读写锁, 注意, 这里使用的是advisory lock.
- 消息乱序问题: 客户端C0获取锁L, 发送一个请求R, R到达之前C0崩溃, 客户端C1获取锁L, 之后, R到达, 由于使用的 是advisory lock, 因此请求R将被执行. 显然这是非法的. 因此必须保证消息的处理顺序和每个参与者 观察到的顺序一致.(参与者? 观察到的顺序?) 可以注意到, 这里消息乱序的仅仅指不同客户端的的消息 乱序, 不包括同一客户端发出的消息. 解决办法是为每个成功的锁请求分配一个 sequencer, 包 含锁的名字, 类型(r/w)和上文提到的lock generation number. 客户端发出请求时附带此 sequencer, chubby通过验证sequencer来判断顺序是否正确.
Events
客户端创建了handle后, 可以订阅一系列事件, 在相应事件发生时, 客户端会收到通知.
Caching
客户端可以缓存文件数据和元数据(meta-data), 为保证缓存一致性, 当chubby要对数据写时, 首先检查 数据是否被客户端缓存, 如果是, 那么先向客户端发送命令, 是客户端将其缓存标记为无效, 命令成功后再 进行写操作.
不仅如此, 客户端还可以缓存打开的handle, 所以当客户端多次调用open打开一个文件时, 只需要第一次 将请求发送到chubby集群.
客户端可以缓存锁. 当有其他客户端请求该锁时, 客户端会收到通知, 已执行相应动作, 如释放锁.
Sessions and KeepAlives
客户端和chubby cell间的连接称为session, 客户端第一次联系cell或master时, 可以请求一个session, session通过周期性的KeepAlives消息来维护, 客户端可以主动结束session.下面主要讨论session的 维持:
每个session都有一个lease, 在lease未超时前chubby保证session的有效性. 当客户端建立一个session 时, 立即向cell发送一个KeepAlive请求, cell并不会立即回复, 而是估计lease即将超时时才会回复, 回复可以延长此lease一定时间, 客户端收到此回复时又立刻发送新的KeepAlive请求, 后面的步骤如上.
lease在下面3种情况下可以被延长:
- on creation of session
- when a master fail-over occurs
- when a master responses to a KeepAlive RPC from client
KeepAlive消息附带其他的信息, 比如通知客户端使缓存无效的事件等.
当lease超时, 即客户端没有及时收到chubby的KeepAlive回复时, lease处于jeopardy, 客户端无法 确定此时session的状态, 因此会将缓存标记为无效, 等待chubby的KeepAlive回复. 此状态会持续一段 时间, 这段时间称为grace period. 如果在此时间内客户端和chubby成功交换了一轮KeepAlive消息, 就会恢复缓存, 开始新的lease, chubby library会向客户端应用发送一个safe event. 如果grace period超时, 则向客户端应用发送一个expired event.
Fail-overs
- master fail后恢复session
如上所述, 如果chubby能在lease超时前或grace peroid超时前选举新的leader, 恢复session等数据 到内存中, 客户端只需要通过和新的master通信即可继续维护session.
- 新master状态恢复
可以从下面几个方向重建状态:
- 通过记录的磁盘的数据
- 通过从客户端获取的数据
- 通过客户端的消息中包含的数据(如打开的handle名)